
Scientific computing with JAX, a case study
Kolen Cheung
March 26th, 2025
An updated version of this talk is presented in the Durham HPC Days 2025 and is available here.
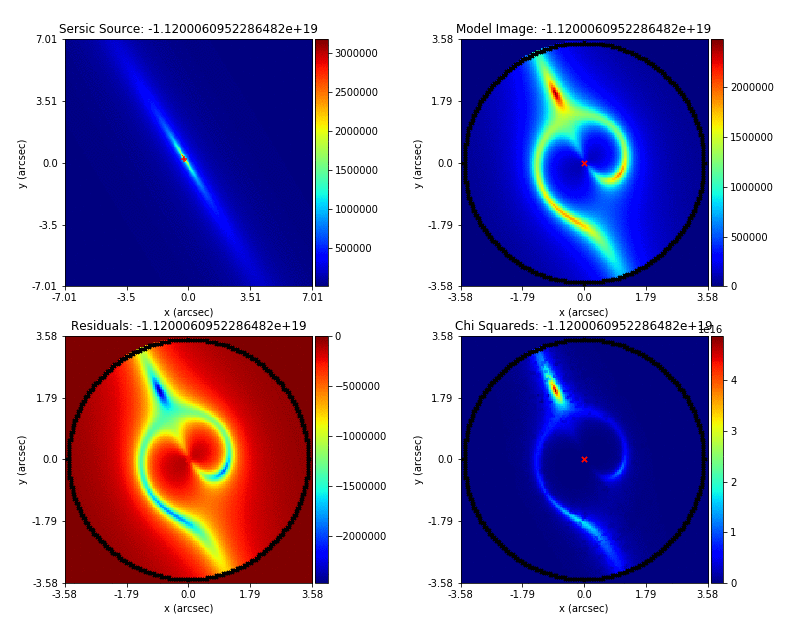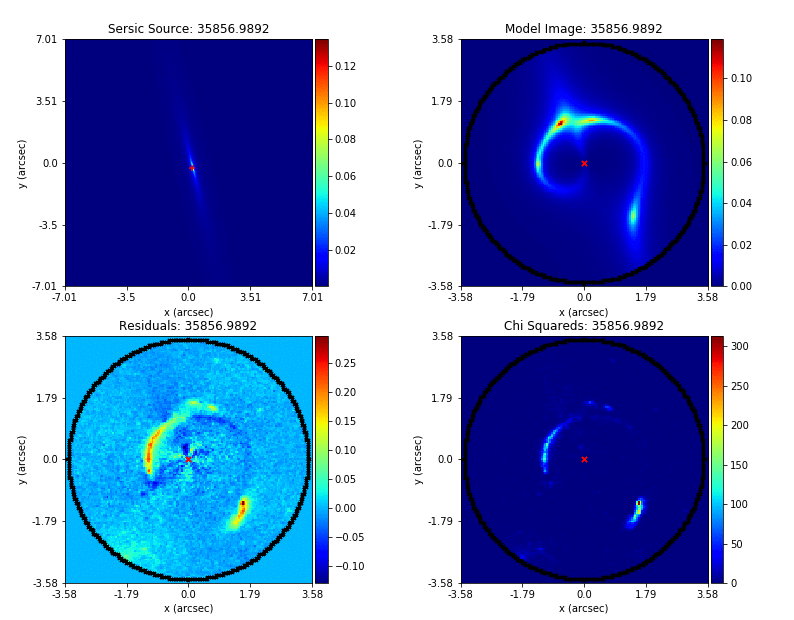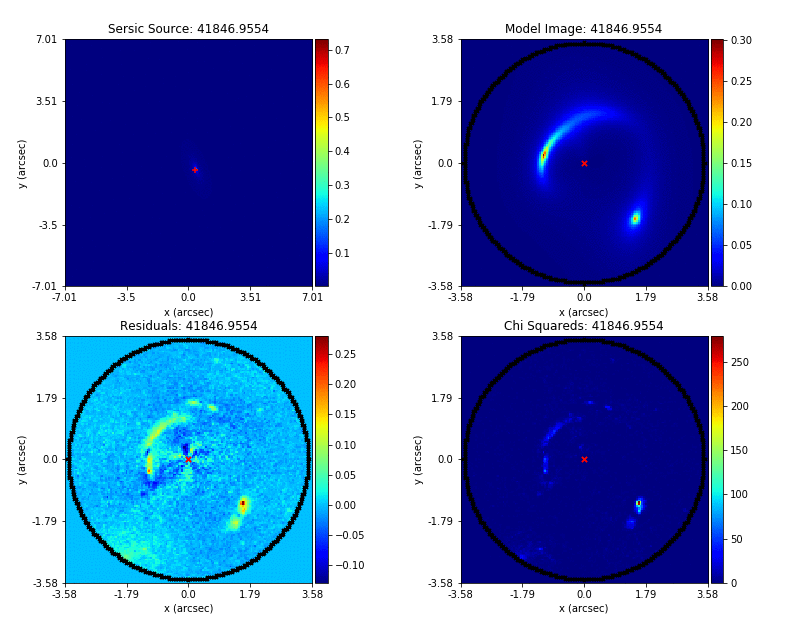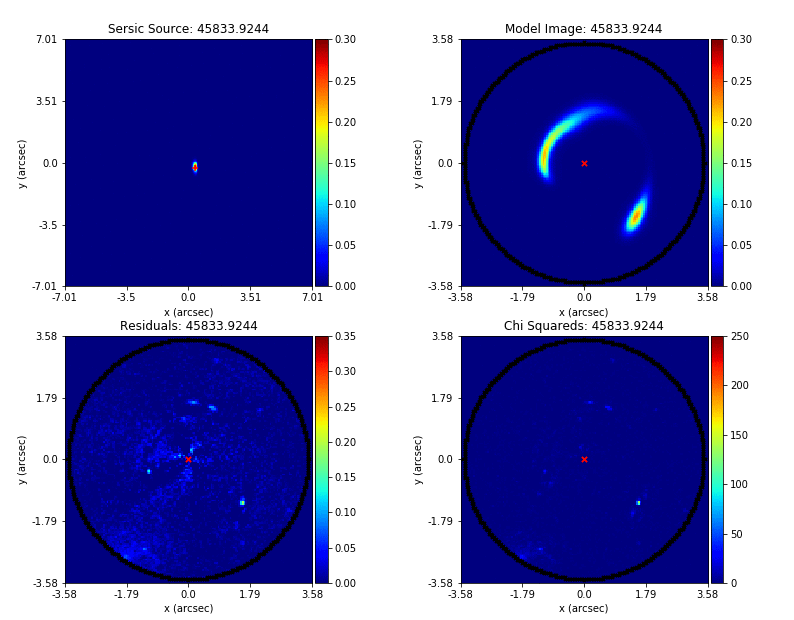
PyAutoFit supports Nested sampling (Dynesty), MCMC (emcee), particle swarm optimization (PySwarms)
Excerpts from project proposal:
… Both codes quote speed ups exceeding 20 times, sometimes going up to factors of 50 times faster. A times ten speed up would be sufficient for the multi-wavelength JWST analysis this proposal aims to do, thus JAX appears to be capable of giving the speed up necessary.
Efficiency gains will come from both making the lens model-fitting auto differentiable and the lensing calculations support accelerated linear algebra (XLA).
\[\tilde{W}_{ij} = \sum_{k=1}^N \frac{1}{n_k^2} \cos(2\pi[(g_{i1} - g_{j1})u_{k0} + (g_{i0} - g_{j0})u_{k1}])\]
@numba.jit(nopython=True, nogil=True, parallel=True)
def w_tilde_curvature_interferometer_from(
noise_map_real: np.ndarray,
uv_wavelengths: np.ndarray,
grid_radians_slim: np.ndarray,
) -> np.ndarray:
w_tilde = np.zeros((grid_radians_slim.shape[0], grid_radians_slim.shape[0]))
for i in range(w_tilde.shape[0]):
for j in range(i, w_tilde.shape[1]):
y_offset = grid_radians_slim[i, 1] - grid_radians_slim[j, 1]
x_offset = grid_radians_slim[i, 0] - grid_radians_slim[j, 0]
for vis_1d_index in range(uv_wavelengths.shape[0]):
w_tilde[i, j] += noise_map_real[vis_1d_index] ** -2.0 * np.cos(
2.0
* np.pi
* (y_offset * uv_wavelengths[vis_1d_index, 0] + x_offset * uv_wavelengths[vis_1d_index, 1])
)
for i in range(w_tilde.shape[0]):
for j in range(i, w_tilde.shape[1]):
w_tilde[j, i] = w_tilde[i, j]
return w_tilde\[\tilde{W}_{ij} = \sum_{k=1}^N \frac{1}{n_k^2} \cos(2\pi[(g_{i1} - g_{j1})u_{k0} + (g_{i0} - g_{j0})u_{k1}])\]
@jax.jit
def w_tilde_curvature_interferometer_from(
noise_map_real: np.ndarray[tuple[int], np.float64],
uv_wavelengths: np.ndarray[tuple[int, int], np.float64],
grid_radians_slim: np.ndarray[tuple[int, int], np.float64],
) -> np.ndarray[tuple[int, int], np.float64]:
# (M, M, 1, 2)
g_ij = grid_radians_slim.reshape(-1, 1, 1, 2) - grid_radians_slim.reshape(1, -1, 1, 2)
# (1, 1, K, 2)
u_k = uv_wavelengths.reshape(1, 1, -1, 2)
return (
jnp.cos(
(2.0 * jnp.pi) *
# (M, M, K)
(
g_ij[:, :, :, 0] * u_k[:, :, :, 1] +
g_ij[:, :, :, 1] * u_k[:, :, :, 0]
)
) /
# (1, 1, K)
jnp.square(noise_map_real).reshape(1, 1, -1)
).sum(2) # sum over k\[\tilde{W}_{ij} = \sum_{k=1}^N \frac{1}{n_k^2} \cos(2\pi[(g_{i1} - g_{j1})u_{k0} + (g_{i0} - g_{j0})u_{k1}])\]
@jax.jit
def w_tilde_curvature_interferometer_from(
noise_map_real: np.ndarray[tuple[int], np.float64],
uv_wavelengths: np.ndarray[tuple[int, int], np.float64],
grid_radians_slim: np.ndarray[tuple[int, int], np.float64],
) -> np.ndarray[tuple[int, int], np.float64]:
# A_mk, m<M, k<K
# assume M > K to put TWO_PI multiplication there
A = grid_radians_slim @ (TWO_PI * uv_wavelengths)[:, ::-1].T
noise_map_real_inv = jnp.reciprocal(noise_map_real)
C = jnp.cos(A) * noise_map_real_inv
S = jnp.sin(A) * noise_map_real_inv
return C @ C.T + S @ S.T\[\tilde{W}_{ij} = \sum_{k=1}^N \frac{1}{n_k^2} \cos(2\pi[(g_{i1} - g_{j1})u_{k0} + (g_{i0} - g_{j0})u_{k1}])\]
@jax.jit
def w_tilde_curvature_interferometer_from(
noise_map_real: np.ndarray[tuple[int], np.float64],
uv_wavelengths: np.ndarray[tuple[int, int], np.float64],
grid_radians_slim: np.ndarray[tuple[int, int], np.float64],
) -> np.ndarray[tuple[int, int], np.float64]:
M = grid_radians_slim.shape[0]
g_2pi = TWO_PI * grid_radians_slim
δg_2pi = g_2pi.reshape(M, 1, 2) - g_2pi.reshape(1, M, 2)
δg_2pi_y = δg_2pi[:, :, 0]
δg_2pi_x = δg_2pi[:, :, 1]
def f_k(
noise_map_real: float,
uv_wavelengths: np.ndarray[tuple[int], np.float64],
) -> np.ndarray[tuple[int, int], np.float64]:
return jnp.cos(δg_2pi_x * uv_wavelengths[0] + δg_2pi_y * uv_wavelengths[1]) * jnp.reciprocal(
jnp.square(noise_map_real)
)
def f_scan(
sum_: np.ndarray[tuple[int, int], np.float64],
args: tuple[float, np.ndarray[tuple[int], np.float64]],
) -> tuple[np.ndarray[tuple[int, int], np.float64], None]:
noise_map_real, uv_wavelengths = args
return sum_ + f_k(noise_map_real, uv_wavelengths), None
res, _ = jax.lax.scan(
f_scan,
jnp.zeros((M, M)),
(
noise_map_real,
uv_wavelengths,
),
)
return resN=64_B=3_K=32768_P=32_S=256
pixi run pytest-benchmark compare 1_N=64_B=3_K=32768_P=32_S=256_NUM_THREADS=1 256_N=64_B=3_K=32768_P=32_S=256_NUM_THREADS=256 --columns=mean,stddev,ops,rounds,iterations --sort=mean--------------------------------------------- benchmark 'w_tilde_curvature_interferometer_from_DataGenerated': 9 tests ---------------------------------------------
Name (time in s) Mean StdDev OPS Rounds Iterations
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_w_tilde_curvature_interferometer_from_jax_compact[DataGenerated] 2.5336 (1.0) 0.0014 (3.59) 0.3947 (1.0) 5 1
test_w_tilde_curvature_interferometer_from_jax_compact_expanded[DataGenerated] 2.5398 (1.00) 0.0021 (5.48) 0.3937 (1.00) 5 1
test_w_tilde_curvature_interferometer_from_numba_compact[DataGenerated] 2.7585 (1.09) 0.0004 (1.0) 0.3625 (0.92) 5 1
test_w_tilde_curvature_interferometer_from_numba_compact_expanded[DataGenerated] 2.7880 (1.10) 0.0011 (3.01) 0.3587 (0.91) 5 1
test_w_tilde_curvature_interferometer_from_original_preload[DataGenerated] 13.6873 (5.40) 0.0009 (2.38) 0.0731 (0.19) 5 1
test_w_tilde_curvature_interferometer_from_original_preload_expanded[DataGenerated] 13.7170 (5.41) 0.0014 (3.57) 0.0729 (0.18) 5 1
test_w_tilde_curvature_interferometer_from_jax[DataGenerated] 3,284.1203 (>1000.0) 0.3030 (799.20) 0.0003 (0.00) 5 1
test_w_tilde_curvature_interferometer_from_numba[DataGenerated] 3,613.6091 (>1000.0) 6.4241 (>1000.0) 0.0003 (0.00) 5 1
test_w_tilde_curvature_interferometer_from_original[DataGenerated] 4,390.4546 (>1000.0) 0.7409 (>1000.0) 0.0002 (0.00) 5 1
--------------------------------------------------------------------------------------------------------------------------------------------------------------------N=32_B=300_K=8192_P=32_S=256
pixi run pytest-benchmark compare --columns=mean,stddev,ops,rounds,iterations --sort=mean 0009_N=32_B=300_K=8192_P=32_S=256_NUM_THREADS=128_cuda----------------------------------------------- benchmark 'w_tilde_curvature_interferometer_from_DataGenerated': 9 tests -----------------------------------------------
Name (time in ms) Mean StdDev OPS Rounds Iterations
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_w_tilde_curvature_interferometer_from_numba_compact[DataGenerated] 2.5029 (1.0) 0.0520 (1.25) 399.5298 (1.0) 260 1
test_w_tilde_curvature_interferometer_from_numba_compact_expanded[DataGenerated] 3.7808 (1.51) 0.0415 (1.0) 264.4928 (0.66) 196 1
test_w_tilde_curvature_interferometer_from_jax_compact_expanded[DataGenerated] 58.6799 (23.44) 9.1624 (220.76) 17.0416 (0.04) 12 1
test_w_tilde_curvature_interferometer_from_jax_compact[DataGenerated] 61.5560 (24.59) 6.8555 (165.18) 16.2454 (0.04) 12 1
test_w_tilde_curvature_interferometer_from_jax[DataGenerated] 143.2451 (57.23) 0.0749 (1.80) 6.9810 (0.02) 5 1
test_w_tilde_curvature_interferometer_from_original_preload[DataGenerated] 840.0727 (335.63) 0.1761 (4.24) 1.1904 (0.00) 5 1
test_w_tilde_curvature_interferometer_from_original_preload_expanded[DataGenerated] 842.6588 (336.67) 0.4933 (11.89) 1.1867 (0.00) 5 1
test_w_tilde_curvature_interferometer_from_numba[DataGenerated] 1,794.1949 (716.83) 14.9648 (360.56) 0.5574 (0.00) 5 1
test_w_tilde_curvature_interferometer_from_original[DataGenerated] 69,304.2738 (>1000.0) 13.5543 (326.58) 0.0144 (0.00) 5 1
------------------------------------------------------------------------------------------------------------------------------------------------------------------------\[F = T^T \tilde{w} T\]
N=64_B=3_K=32768_P=32_S=256
pixi run pytest-benchmark compare 1_N=64_B=3_K=32768_P=32_S=256_NUM_THREADS=1 256_N=64_B=3_K=32768_P=32_S=256_NUM_THREADS=256 --columns=mean,stddev,ops,rounds,iterations --sort=mean--------------------------------------------- benchmark 'curvature_matrix_DataGenerated': 11 tests ---------------------------------------------
Name (time in ms) Mean StdDev OPS Rounds Iterations
------------------------------------------------------------------------------------------------------------------------------------------------
test_curvature_matrix_numba_sparse[DataGenerated] 10.2812 (1.0) 0.1751 (1.50) 97.2652 (1.0) 94 1
test_curvature_matrix_jax[DataGenerated] 20.0919 (1.95) 1.5245 (13.03) 49.7714 (0.51) 30 1
test_curvature_matrix_jax_sparse[DataGenerated] 36.8161 (3.58) 1.2018 (10.27) 27.1620 (0.28) 9 1
test_curvature_matrix_numba_compact_sparse[DataGenerated] 52.9714 (5.15) 0.1170 (1.0) 18.8781 (0.19) 19 1
test_curvature_matrix_jax_BCOO[DataGenerated] 63.1237 (6.14) 3.4937 (29.87) 15.8419 (0.16) 7 1
test_curvature_matrix_original_preload_direct[DataGenerated] 99.3323 (9.66) 0.1512 (1.29) 10.0672 (0.10) 11 1
test_curvature_matrix_numba[DataGenerated] 126.0225 (12.26) 0.1512 (1.29) 7.9351 (0.08) 8 1
test_curvature_matrix_original[DataGenerated] 126.5191 (12.31) 0.1542 (1.32) 7.9039 (0.08) 8 1
test_curvature_matrix_numba_compact_sparse_direct[DataGenerated] 140.8911 (13.70) 0.6626 (5.66) 7.0977 (0.07) 8 1
test_curvature_matrix_jax_compact_sparse[DataGenerated] 533.6890 (51.91) 5.1037 (43.63) 1.8738 (0.02) 5 1
test_curvature_matrix_jax_compact_sparse_BCOO[DataGenerated] 537.2100 (52.25) 2.2710 (19.42) 1.8615 (0.02) 5 1
------------------------------------------------------------------------------------------------------------------------------------------------N=32_B=300_K=8192_P=32_S=256
pixi run pytest-benchmark compare --columns=mean,stddev,ops,rounds,iterations --sort=mean 0009_N=32_B=300_K=8192_P=32_S=256_NUM_THREADS=128_cuda---------------------------------------------------- benchmark 'curvature_matrix_DataGenerated': 11 tests ----------------------------------------------------
Name (time in us) Mean StdDev OPS Rounds Iterations
--------------------------------------------------------------------------------------------------------------------------------------------------------------
test_curvature_matrix_jax[DataGenerated] 260.5957 (1.0) 29.3714 (1.0) 3,837.3618 (1.0) 1295 1
test_curvature_matrix_jax_BCOO[DataGenerated] 3,078.2068 (11.81) 35.9463 (1.22) 324.8645 (0.08) 5 1
test_curvature_matrix_jax_compact_sparse_BCOO[DataGenerated] 3,207.3388 (12.31) 107.0798 (3.65) 311.7850 (0.08) 293 1
test_curvature_matrix_numba_sparse[DataGenerated] 5,548.5175 (21.29) 64.3711 (2.19) 180.2283 (0.05) 146 1
test_curvature_matrix_jax_compact_sparse[DataGenerated] 7,190.9015 (27.59) 35.7355 (1.22) 139.0646 (0.04) 134 1
test_curvature_matrix_numba[DataGenerated] 18,187.5003 (69.79) 5,603.6081 (190.78) 54.9828 (0.01) 207 1
test_curvature_matrix_original[DataGenerated] 18,279.9851 (70.15) 6,052.1386 (206.06) 54.7046 (0.01) 9 1
test_curvature_matrix_jax_sparse[DataGenerated] 19,786.7200 (75.93) 42.9344 (1.46) 50.5389 (0.01) 6 1
test_curvature_matrix_numba_compact_sparse[DataGenerated] 32,605.2243 (125.12) 248.8764 (8.47) 30.6699 (0.01) 30 1
test_curvature_matrix_numba_compact_sparse_direct[DataGenerated] 1,362,329.9249 (>1000.0) 1,366.9112 (46.54) 0.7340 (0.00) 5 1
test_curvature_matrix_original_preload_direct[DataGenerated] 25,218,633.7856 (>1000.0) 8,722.4870 (296.97) 0.0397 (0.00) 5 1
--------------------------------------------------------------------------------------------------------------------------------------------------------------export MKL_NUM_THREADS={num_threads}
export MKL_DOMAIN_NUM_THREADS="MKL_BLAS={num_threads}"
export MKL_DYNAMIC=FALSE
export OMP_NUM_THREADS={num_threads}
export OMP_PLACES=threads
export OMP_PROC_BIND=spread
export OMP_DYNAMIC=FALSE
export NUMEXPR_NUM_THREADS={num_threads}
export OPENBLAS_NUM_THREADS={num_threads}
export NUMBA_NUM_THREADS={num_threads}
export XLA_FLAGS="--xla_cpu_multi_thread_eigen=true intra_op_parallelism_threads={num_threads} --xla_force_host_platform_device_count={num_threads}"
export TF_NUM_INTEROP_THREADS=1
export TF_NUM_INTRAOP_THREADS={num_threads}Pull \(K\) outside the log-likelihood loop.